Qwen/Qwen3-ASR-1.7B
The Qwen3-ASR family includes Qwen3-ASR-1.7B and Qwen3-ASR-0.6B, which support language identification and ASR for 52 languages and dialects.
Automatic Speech Recognition
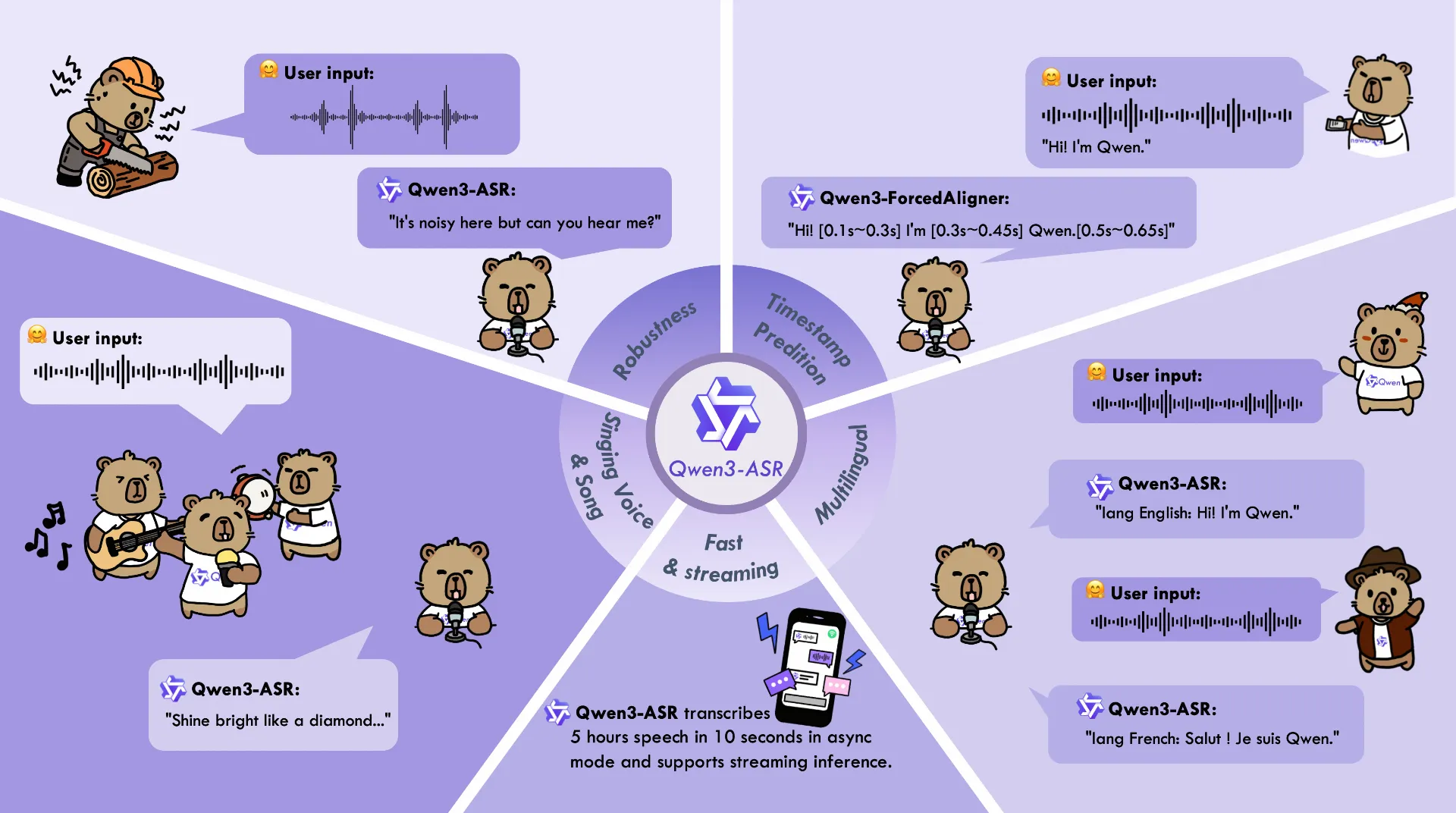
The Qwen3-ASR family includes Qwen3-ASR-1.7B and Qwen3-ASR-0.6B, which support language identification and ASR for 52 languages and dialects. Both leverage large-scale speech training data and the strong audio understanding capability of their foundation model, Qwen3-Omni. Experiments show that the 1.7B version achieves state-of-the-art performance among open-source ASR models and is competitive with the strongest proprietary commercial APIs. Here are the main features:
- All-in-one: Qwen3-ASR-1.7B and Qwen3-ASR-0.6B support language identification and speech recognition for 30 languages and 22 Chinese dialects, so as to English accents from multiple countries and regions.
- Excellent and Fast: The Qwen3-ASR family ASR models maintains high-quality and robust recognition under complex acoustic environments and challenging text patterns. Qwen3-ASR-1.7B achieves strong performance on both open-sourced and internal benchmarks. While the 0.6B version achieves accuracy-efficient trade-off, it reaches 2000 times throughput at a concurrency of 128. They both achieve streaming / offline unified inference with single model and support transcribe long audio.
- Novel and strong forced alignment Solution: We introduce Qwen3-ForcedAligner-0.6B, which supports timestamp prediction for arbitrary units within up to 5 minutes of speech in 11 languages. Evaluations show its timestamp accuracy surpasses E2E based forced-alignment models.
- Comprehensive inference toolkit: In addition to open-sourcing the architectures and weights of the Qwen3-ASR series, we also release a powerful, full-featured inference framework that supports vLLM-based batch inference, asynchronous serving, streaming inference, timestamp prediction, and more.
Model Architecture
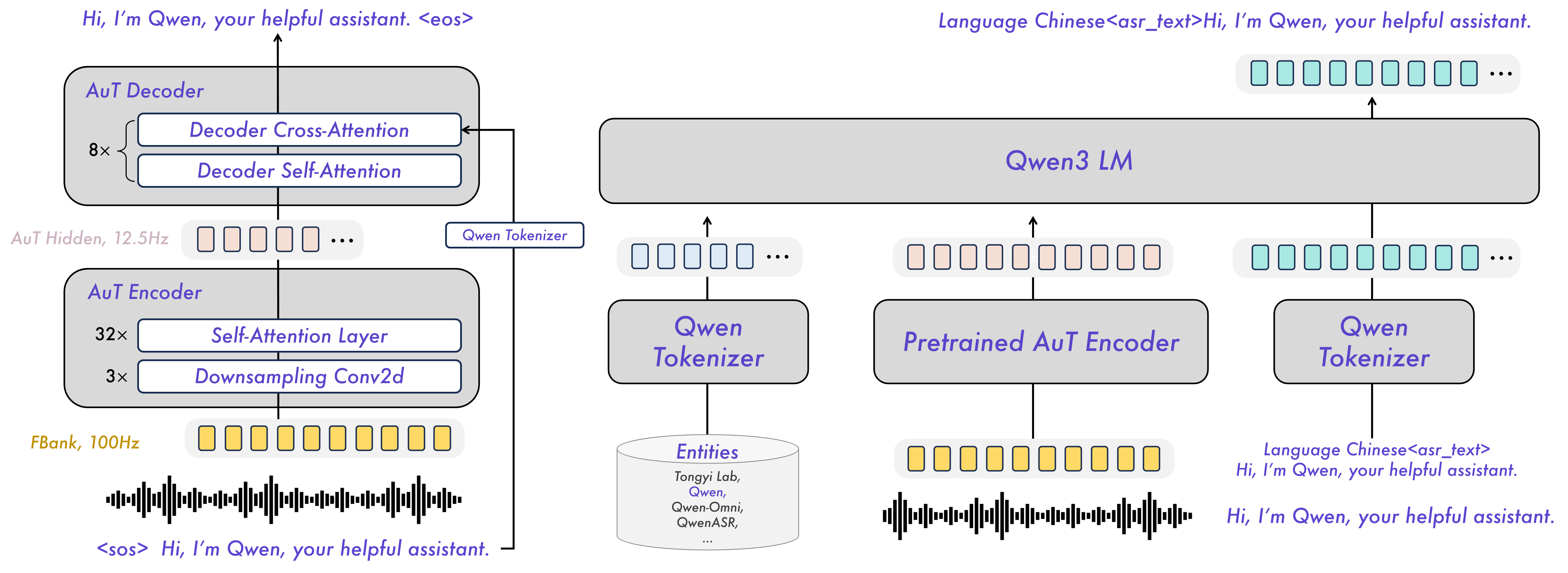
🔎