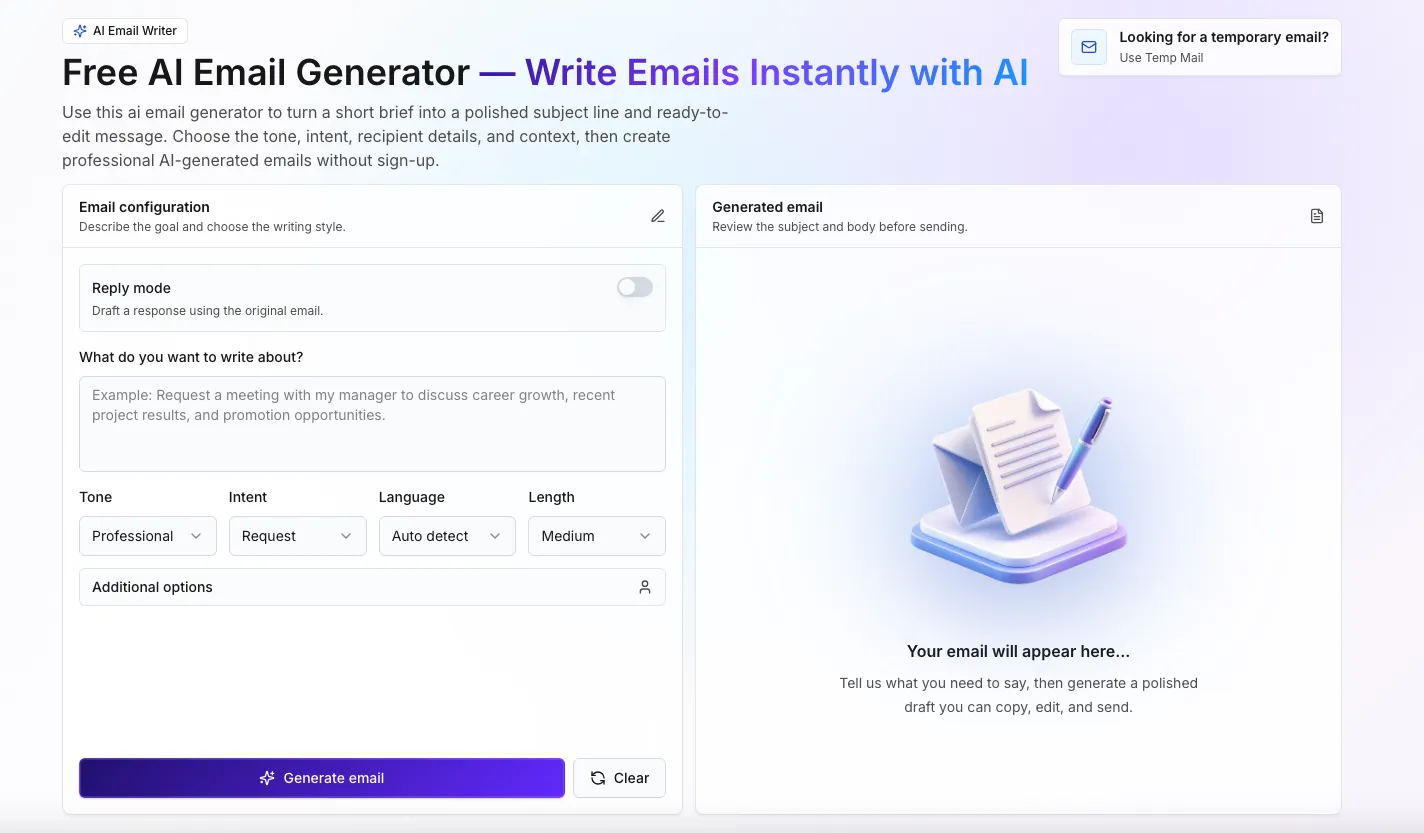
Discover The Best AI Websites & Models
27931 AIs and 88 categories in the best AI tools directory.

Latest AI Models
zai-org/GLM-4.7
A state-of-the-art text generation model with 358B parameters, supporting English and Chinese, optimized for agentic reasoning, coding, and complex tool use.
MiniMaxAI/MiniMax-M2.1
MiniMax M2.1 is a state-of-the-art (SOTA) model designed specifically for real-world development and autonomous agents, focusing on coding, tool use, and long-horizon planning.
moonshotai/Kimi-K2.5
Kimi K2.5 is an open-source, native multimodal agentic model built through continual pretraining on approximately 15 trillion mixed visual and text tokens atop Kimi-K2-Base
Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice
The Qwen3-TTS-Tokenizer-12Hz model which can encode the input speech into codes and decode them back into speech.
openbmb/MiniCPM-o-4_5
A Gemini 2.5 Flash Level MLLM for Vision, Speech, and Full-Duplex Mulitmodal Live Streaming on Your Phone
deepseek-ai/DeepSeek-OCR-2
DeepSeek-OCR is a model designed to explore the boundaries of visual-text compression, investigating the role of vision encoders from an LLM-centric viewpoint.
zai-org/GLM-OCR
GLM-OCR is a multimodal OCR model for complex document understanding, built on the GLM-V encoder–decoder architecture
PaddlePaddle/PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 is an advanced next-generation model of PaddleOCR-VL, achieving a new state-of-the-art accuracy of 94.5% on OmniDocBench v1.5
Qwen/Qwen3-ASR-1.7B
The Qwen3-ASR family includes Qwen3-ASR-1.7B and Qwen3-ASR-0.6B, which support language identification and ASR for 52 languages and dialects.
Qwen/Qwen3-Coder-Next
an open-weight language model designed specifically for coding agents and local development
Tongyi-MAI/Z-Image
An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
openai/whisper-large-v3
Convert speech in audio to text
openai/sora-2-pro
OpenAI's Most advanced synced-audio video generation
openai/gpt-image-1.5
OpenAI's latest image generation model with better instruction following and adherence to prompts
tencent/hunyuan-image-3
A powerful native multimodal model for image generation (PrunaAI squeezed)
stability-ai/stable-diffusion-3.5-large
A text-to-image model that generates high-resolution images with fine details. It supports various artistic styles and produces diverse outputs from the same prompt, thanks to Query-Key Normalization.
google/nano-banana
Google's latest image editing model in Gemini 2.5
prunaai/p-image
A sub 1 second text-to-image model built for production use cases.
recraft-ai/recraft-v3
Recraft V3 (code-named red_panda) is a text-to-image model with the ability to generate long texts, and images in a wide list of styles. As of today, it is SOTA in image generation, proven by the Text-to-Image Benchmark by Artificial Analysis
google/imagen-4-ultra
Use this ultra version of Imagen 4 when quality matters more than speed and cost
FAQ
Ready to discover your next AI tool or model?
Explore thousands of curated AI products across categories, compare standout tools faster, and find the right fit for your next workflow.