PaddlePaddle/PaddleOCR-VL-1.5
VisitPaddleOCR-VL-1.5 is an advanced next-generation model of PaddleOCR-VL, achieving a new state-of-the-art accuracy of 94.5% on OmniDocBench v1.5

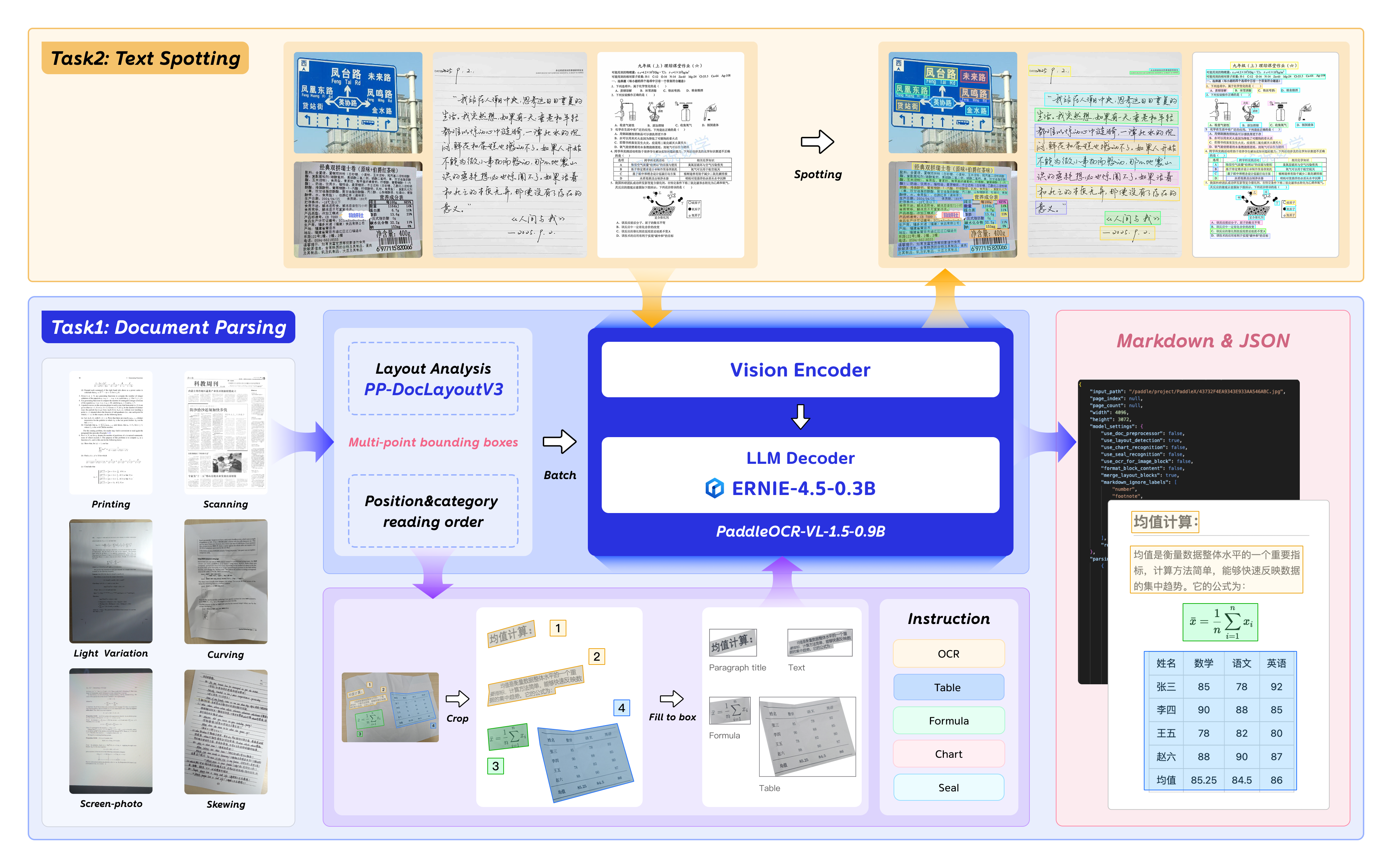
PaddleOCR-VL-1.5 is an advanced next-generation model of PaddleOCR-VL, achieving a new state-of-the-art accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions—including scanning artifacts, skew, warping, screen photography, and illumination—we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model’s capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency.
Key Capabilities of PaddleOCR-VL-1.5
-
With a parameter size of 0.9B, PaddleOCR-VL-1.5 achieves 94.5% accuracy on OmniDocBench v1.5, surpassing the previous SOTA model PaddleOCR-VL. Significant improvements are observed in table, formula, and text recognition.
-
It introduces an innovative approach to document parsing by supporting irregular-shaped localization, enabling accurate polygonal detection under skewed and warped document conditions. Evaluations across five real-world scenarios—scanning, skew, warping, screen-photography, and illumination—demonstrate superior performance over mainstream open-source and proprietary models.
-
The model introduces text spotting (text-line localization and recognition), along with seal recognition, with all corresponding metrics setting new SOTA results in their respective tasks.
-
PaddleOCR-VL-1.5 further strengthens its capability in specialized scenarios and multilingual recognition. Recognition performance is improved for rare characters, ancient texts, multilingual tables, underlines, and checkboxes, and language coverage is extended to include China's Tibetan script and Bengali.
-
The model supports automatic cross-page table merging and cross-page paragraph heading recognition, effectively mitigating content fragmentation issues in long-document parsing.
Model Architecture
Similar to PaddlePaddle/PaddleOCR-VL-1.5
deepseek-ai/DeepSeek-OCR-2
DeepSeek-OCR is a model designed to explore the boundaries of visual-text compression, investigating the role of vision encoders from an LLM-centric viewpoint.
zai-org/GLM-OCR
GLM-OCR is a multimodal OCR model for complex document understanding, built on the GLM-V encoder–decoder architecture