Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice
The Qwen3-TTS-Tokenizer-12Hz model which can encode the input speech into codes and decode them back into speech.
Text-to-Speech
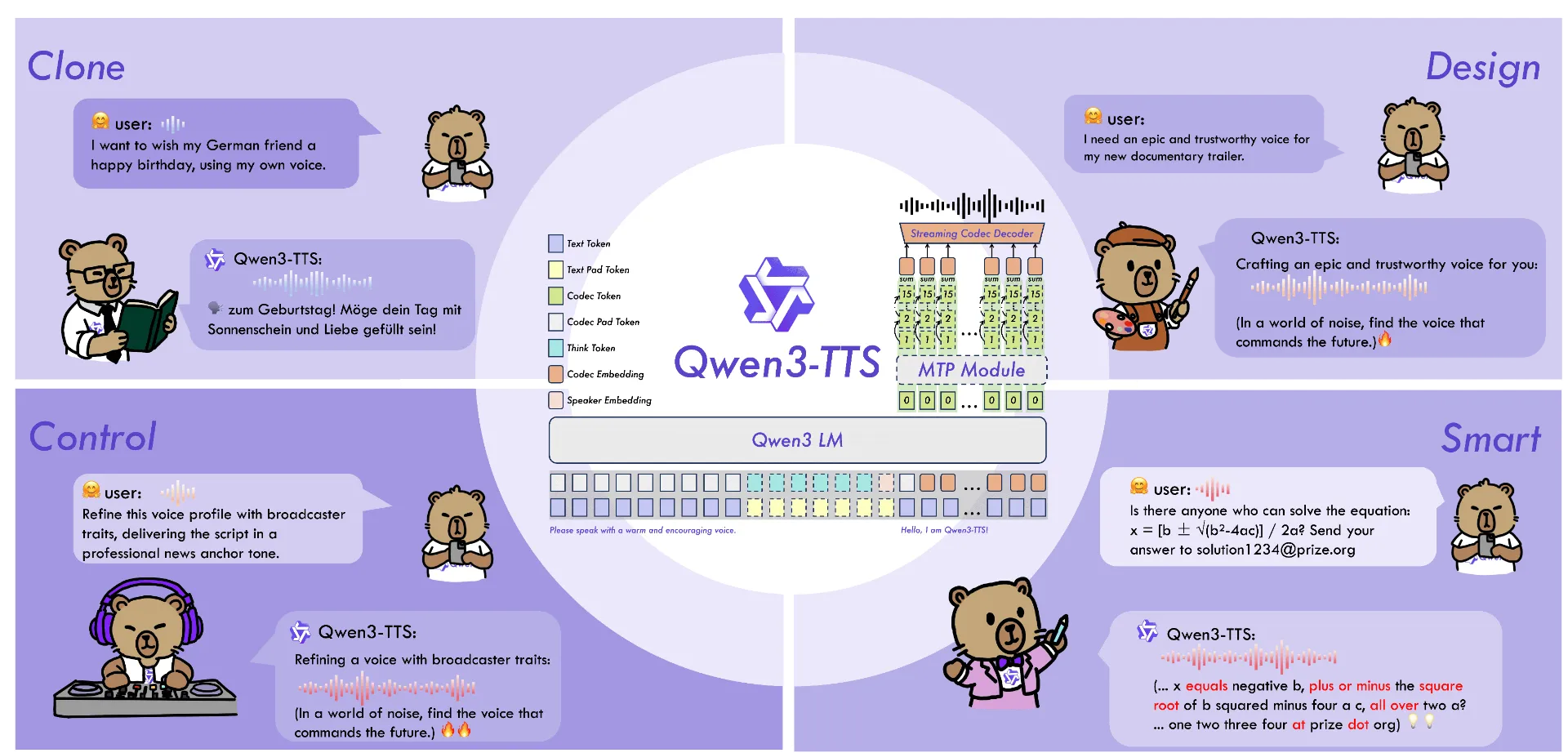
Qwen3-TTS covers 10 major languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian) as well as multiple dialectal voice profiles to meet global application needs. In addition, the models feature strong contextual understanding, enabling adaptive control of tone, speaking rate, and emotional expression based on instructions and text semantics, and they show markedly improved robustness to noisy input text. Key features:
- Powerful Speech Representation: Powered by the self-developed Qwen3-TTS-Tokenizer-12Hz, it achieves efficient acoustic compression and high-dimensional semantic modeling of speech signals. It fully preserves paralinguistic information and acoustic environmental features, enabling high-speed, high-fidelity speech reconstruction through a lightweight non-DiT architecture.
- Universal End-to-End Architecture: Utilizing a discrete multi-codebook LM architecture, it realizes full-information end-to-end speech modeling. This completely bypasses the information bottlenecks and cascading errors inherent in traditional LM+DiT schemes, significantly enhancing the model’s versatility, generation efficiency, and performance ceiling.
- Extreme Low-Latency Streaming Generation: Based on the innovative Dual-Track hybrid streaming generation architecture, a single model supports both streaming and non-streaming generation. It can output the first audio packet immediately after a single character is input, with end-to-end synthesis latency as low as 97ms, meeting the rigorous demands of real-time interactive scenarios.
- Intelligent Text Understanding and Voice Control: Supports speech generation driven by natural language instructions, allowing for flexible control over multi-dimensional acoustic attributes such as timbre, emotion, and prosody. By deeply integrating text semantic understanding, the model adaptively adjusts tone, rhythm, and emotional expression, achieving lifelike “what you imagine is what you hear” output.